

アーティスト一覧をCSV書き出ししてみよう!
こんにちは。どんぶラッコです。
前回、童謡の曲名を取得してくるコードを通じて、スクレイピングの基礎についてお話ししました。

せっかく作ったんだから、データを保存したいよね!
ということで、今回は別のお題を解説しながら、実際にデータをCSVに書き出す流れをサンプルコードで解説していきます!
今回使うのは下記2つのWikipediaサイトです。
一覧形式でアーティストがまとまっているので、取得しやすそうというのが理由です←
サンプルコード
1. アーティスト名データを取得する
※本当は関数化したほうがいいですが、読み流して理解できるように関数化していません
import requests
from bs4 import BeautifulSoup
import csv
db_artists=[]
# 個人アーティスト一覧を取得
URL = 'https://ja.wikipedia.org/wiki/%E3%83%9D%E3%83%94%E3%83%A5%E3%83%A9%E3%83%BC%E9%9F%B3%E6%A5%BD%E3%81%AE%E9%9F%B3%E6%A5%BD%E5%AE%B6%E4%B8%80%E8%A6%A7_(%E6%97%A5%E6%9C%AC%E3%83%BB%E5%80%8B%E4%BA%BA)'
res = requests.get(URL)
soup = BeautifulSoup(res.text, 'html.parser')
data = soup.select('.mw-parser-output > ul > li > a')
for d in data[3:]:
db_artists.append(d.string)
# 団体アーティスト一覧を取得
URL = 'https://ja.wikipedia.org/wiki/%E3%83%9D%E3%83%94%E3%83%A5%E3%83%A9%E3%83%BC%E9%9F%B3%E6%A5%BD%E3%81%AE%E9%9F%B3%E6%A5%BD%E5%AE%B6%E4%B8%80%E8%A6%A7_(%E6%97%A5%E6%9C%AC%E3%83%BB%E3%82%B0%E3%83%AB%E3%83%BC%E3%83%97)'
res = requests.get(URL)
soup = BeautifulSoup(res.text, 'html.parser')
data = soup.select('.mw-parser-output > ul > li > a')
for d in data[2:]:
db_artists.append(d.string)db_artists を確認すると、アーティスト名がそれぞれ取得できていることがわかります。

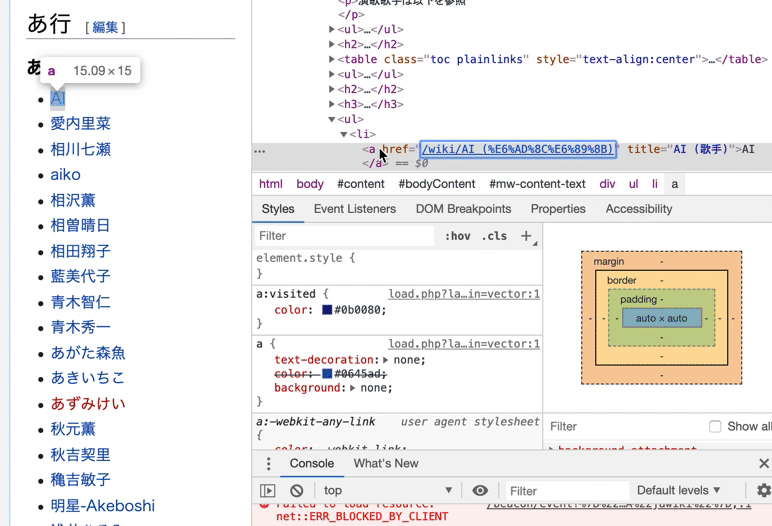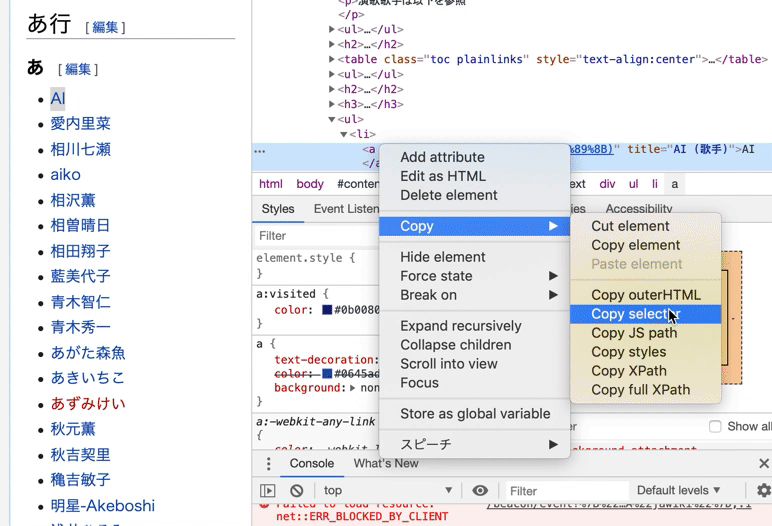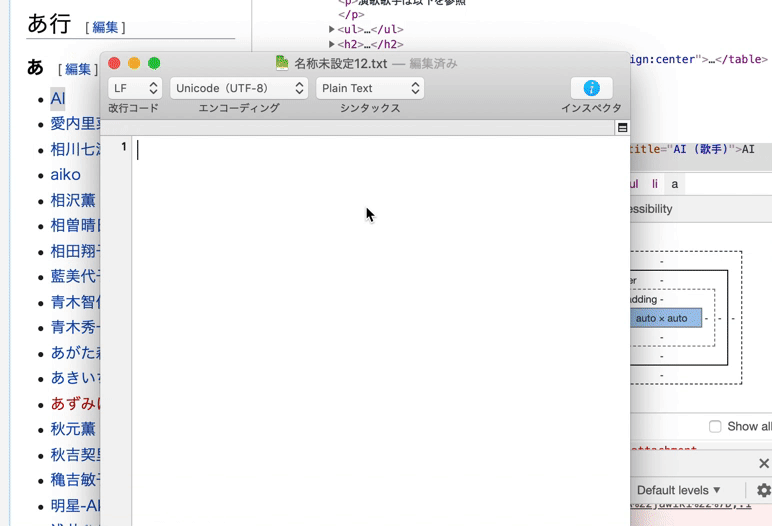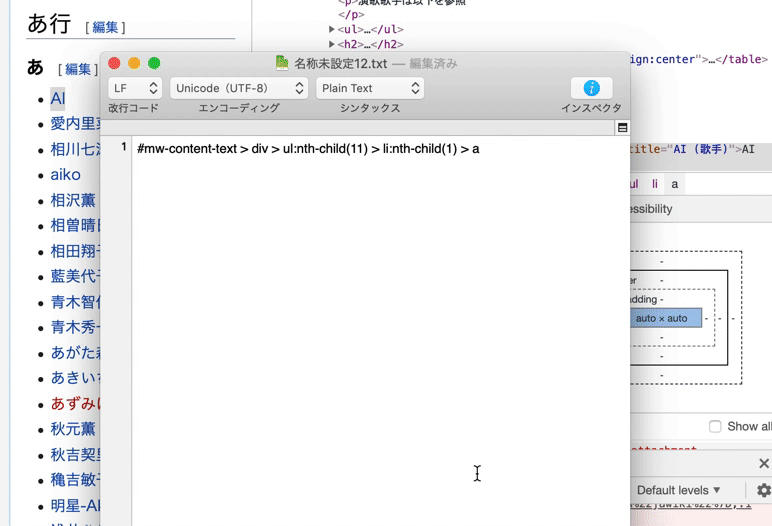
プログラミングコードの内容にsoup_select()で.mw-parser-output > ul > li > a と指定している理由は、今回はアナログにHTMLを分析してセレクタを定義しました。

今回ほど単純な構造ではないWebサイトの場合は、Chromeの検証ツールから “Copy Selector” 機能を使ってセレクタを発見する方法が良いでしょう。
2. CSV で書き出す
では次に、 db_artists 配列をCSVで書き出す処理を書いてみましょう!
今回はcsvライブラリを使ってみましょう。
import csv
with open('pop_artists.csv', 'w') as f:
writer = csv.writer(f)
for artists in db_artists:
writer.writerow([artists])めっちゃ簡単ですね!

無事に書き出されていることが確認できるかと思います。
いかがだったでしょうか?ぜひみなさんも試してみてくださいね!


















